
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Latent space
- StarGAN
- Styletransfer
- PatchGAN
- Markov Random field
- pix2pix
- PGGAN
- DCGAN
- Unsupervised learning
- Ian GoodFellow
- LSGAN
- Representation learning
- conditional GAN
- clova
- ICLR
- xai
- Mutual Information
- self-supervised learning
- InfoGAN
- GAN
- Image-to-image translation
- PatchDiscriminator
- Unsupervised Representation Learning
- Computer Vision
- Generative model
- Gradien Vanishing
- Today
- Total
AI with U-Seminar, Daneil Jeong
Dense Net(2018)논문 정리 본문
Dense Net 논문 정리
안녕하세요, 블로그에 처음 공부 내용을 정리하게 되었습니다.
저도 아직 가야할 길이 멀게만 느껴지지만, 열심히 공부하는 누군가가
저의 글을 보고 함께 달릴 수 있으시길 바라며 글을 올립니다.
<Dense Net 논문 링크>
Densely Connected Convolution Networks - Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weingberger.
의견이나 피드백, 혹은 같이 토론할 거리가 있으시면 댓글에 남겨주세요!
1. Abstract
Input에 가까운 Layer와 Output에 가까운 Layer 사이에 Shorter Connection(아래 그림 참조)이 있는 경우, convolutional network가 train을 하는 데 있어서 좀 더 깊어지고(deeper), 정확해지고, 효율적이게 될 수 있다. 이 때 Dense Convolutional Network는 각 layer들을 모든 다른 layer들과 feed-foward로 연결한 형태이다. (따라서 L(L+1)/2의 direct connections이 존재한다!!) 각 layer들의 이전 layer의 feature map들은 그 layer의 input으로 사용된다(즉 아래 그림과 같이 앞으로 계속 feed 해준다). Dense net은 vanishing gradient 문제를 해결하고, feature propgation을 강화하고(아마 모든 layer의 feature map을 연결해서 그런듯 하다!), feature의 재사용을 도와 parameter 숫자를 줄인다(computational efficiency가 높다). DenseNet은 benchmark task로 CIFAR10, CIFAR100, SVHN, ImageNet을 사용하였다.
code랑 pre-trained model은 다음 링크에서 얻을 수 있다.
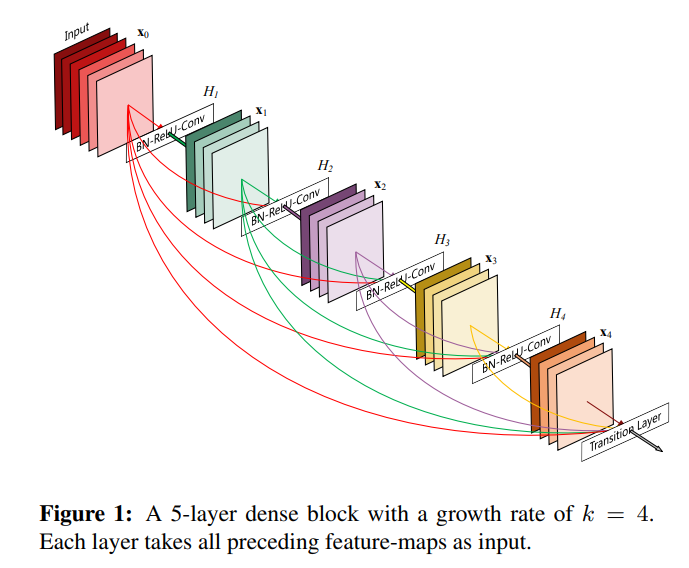
2. Introduction
CNN은 visual object recognition에서 가장 탁월한 성능을 보이는 ML 기법이다. (LeNet5 -> 5layers, VGG -> 19 layers, Highway Network & ResNet -> 100 layer이상) 하지만 CNN 모델이 깊어질 수록(deep), input의 정보나 gradient가 layer를 거치면서 사라질 수 있는(vanish and 'wash out') 문제가 존재한다. ResNet과 Highway Network는 identity connection(자기 자신을 다시 feed시켜주는 방식)을 사용하여 이것을 해결하려 하였다. Stochastic depth는 Resnet의 layer를 random하게 없애주어(dropping layer) 크기를 줄였다(shorten -> input과 gradient가 보다 잘 전달되게). Fractal Net은 각기 다른 숫자의 convolutional block들로 이루어진 parallel layer들의 sequence를 여러 번 반복시켜 short path를 유지한 채 nominal depth를 크게 하였다. 하지만 이와 같은 모든 방식들의 공통점은 앞선(early) 레이어로 부터 그 후(later) 레이어로의 short path를 만드는 것이다. 따라서 Dense Net은 이를 해결하기 위해 모든 layer를 직접 연결하였다(정보를 최대한 많이 전달해보자!) feed-foward의 특성을 유지하기 위해, 각 layer는 모든 이전 layer들로 부터 input을 추가로 받아 그 layer의 feature map에 통과 시킨다. 단순히 feature들을 더하던 Resnet과 달리(identity(자기 자신)을 더해주던 방식), Dense Net은 feature들을 모두 합쳐준다.(Concatenate) 결국 Dense Net은 L번째 layer에는 L(L+1)/2만큼의 연결선이 존재하게 된다는 뜻이다.(Resnet같은 경우에는 L만큼만 존재)
Dense Net의 직관적인 특징들은 적은 수의 parameter를 필요로 하는 것과, 또한 불필요한(redundant) feature map을 재학습(re-learn)할 필요가 없다는 것이다. Drop 방식을 사용하는 ResNet(RNN과 유사한 모습)은 layer 수는 줄였지만 여전히 많은 양의 parameter가 필요하다(각 layer마다 weight이 다르므로). DenseNet의 layer들은 아주 narrow하고(12 filters per layer), 적은 양의 feature map들을 합쳐 이용하며 남은 feature map들이 바뀌지 않게 한다(즉 마지막 결과값(classification 결과)는 모든 feature map을 기반으로 이루어진다) DenseNet의 또 다른 장점은 gradient와 information의 흐름이 개선되었다는 것이다(train하기 쉬워졌다). 모든 layer이 선행된 다른 layer들과 직접적으로 연결되어 있기 때문에, loss function이나 input signal의 gradient 역시 직접적으로 접근하는 것이 가능하다(따라서 deeper한 구조를 만드는 것이 가능하다 -> gradient vanishing이 없어졌기 때문일 것이다) DenseNet은 regularization effect 역시 있기 상대적으로 때문에 작은 train set을 이용하여도 overfitting 문제에서 자유로울 수 있다. DenseNet은 앞서 설명한 4가지의 benchmark들을 이용하여 적은 parameter들로 상당한 효과를 보일 수 있음을 증명해낼 것이다.
3. Related Work
a. Layer by Layer로 학습한 fully connected multi-layer perceptrons
b. batch gradient descent를 사용한 fully connected cascade networks
위와 같은 두 방법은 small dataset에만 효과적이다. (few hundread params)
c. skip-connection을 이용한 multi-level features CNN -> cross-layer connection의 선구자적 역할!
d. HighWay Network -> 처음으로 100개 이상의 layer를 갖는 end-to-end network를 효과적으로 학습
(gating unit이 있는 bypassing path를 활용하였다고 한다)
e. ResNet은 bypassing path를 pure identitiy(자기 자신)을 사용한 것이다! -> COCO, ImageNet 굿
f. stochastic depth 개념이 ResNet의 성능을 높였다(drop layer)
-> 즉 모든 layer가 필요하지 않으며 불필요한 layer나 parameter의 양이 상당할 것이다!!
-> DenseNet은 여기에서 idea를 얻고 출발하였다.
g. ResNet의 pre-activation은 1000개가 넘는 layer에 대하여 효과적인 train 성능을 가져왔다.
h. Google Net의 Inception module은 network의 width를 넓히는 데 공헌하였다.
Inception Module이 바로 feature map들을 합치는(concatenate) 방식을 처음 사용!!(각기 다른 feature size들에 기반하였다)
i. 이를 통해 일반화된 wide generalized residual block 개념이 ResNet을 변형하여 등장
j. FractalNet 역시 wide network 구조를 사용한 case
-> DenseNet은 그러나 width, depth에 집중하지 않았다. feature 재사용(reuse)가 핵심개념! (condese한 모델, parameter의 효율성을 높이는 모델)
concat한 feature map들은(각기 다른 layer에서 만든) input의 variation을 증가시켜 효과적인 학습이 가능하게 하였으며,
Inception Network에 비해 단순하고 효율적이다.
k. NIN -> micro multi-layer perceptrons을 convolutional layer filter에 적용시켜 feature의 복잡성을 키운다
l. DSN -> gradient의 흐름을 개선한 방법
m. Ladder Network, DFNs 등등.... 다양한 방법이 존재
4. DenseNet이란??
단일 이미지(x0)가 L개의 H layer들(Batch Normalization, ReLU, Pooling, Convolution 등등을 포함하는 layer) Convolutional Network을 통과하는 경우를 생각해보자. l번째 layer의 출력(output)을 xl이라 부른다(denote).
Resnet
Resnet은 아래와 같이 H에 의한 output과 identity function(출력 그자체!)의 합으로 layer의 출력값을 표현한다.

Resnet은 identity를 이용하기 때문에 gradient의 layer 사이에서 직접적으로(directly) 흐를 수 있다. (즉, gradient의 흐름이 개선되었다, 정말로 지름길(short cut)이다!!) 그러나, 출력값이 합(summation)으로 표현되기 때문에 정보의 흐름은 저해(impede)할 수 있다. (아마도, 합으로 표현되기 때문에 이전 layer들의 정보(값)들이 충분히 전달되지 못할 수도 있다, 예를 들어 H에 의한 output의 영향력이 큰 경우 여러 layer를 넘어온 정보 값들은 출력에 큰 영향을 끼치지 못할 가능성이 존재한다.) 이 부분을 해결하기 위하는 것이 바로 Dense connect!!!
Dense Connectivity
모든 layer를 그 뒤에 존재하는(후속, subsequent) layer들에 연결해주는 것이 새로 고안된 방법이다. 결과적으로 l번째 layer는 이전에 존재하는 l개의 feature map(x0까지 포함)을 입력값으로 받는 셈이다.

위 식에서 x0~xl-1은 모든 입력 값을 나란히 합쳐준 형태(concatenate)이다. multiple input을 densely 연결하였기 때문에, 이와 같은 모델을 DenseNet이라 부른다.
a. Composite Function -> H는 Batch Normalization + ReLU + 3 x 3 Convolution의 3개의 layer로 구성된다.
b. Pooling layer -> feature map의 사이즈가 달라지는 경우에는 concatenation은 문제가 될 수 있다.(size가 다르면 평행하게 합치는 것이 불가능하다) 이 부분을 해결하기 위해 down-sampling을 이용하여 feature map의 크기를 바꾼다. down sampling의 활용을 위해 network를 여러 개의 dense block로 나눈다. block 사이의 layer(convolution과 pooling을 하는)을 transition layer라 부른다. Dense Net의 실험에서 사용된 transition layer는 batch_normalization과 1x1 conv layer, 2x2 average pooling layer로 이루어져 있다.

c. Growth rate -> 각 H의 함수에서는 k개의 feature map을 만들어낸다. 이 때 입력은 input의 채널 개수 k0와 이전 (l-1)개의 layer에서 만들어진 k개의 feature map이다. Dense Net이 다른 Network에 비해 두드러지는 특징은 layer가 좁다(narrow)는 것이다.(e.g. k = 12) 이 때 k 값을 hyper parameter인 growth rate이라 부른다. 상대적으로 작은 growth rate을 가지고 효과적인 결과를 낼 수 있음을 test 결과에 나타낸다. k값은 다음과 같이 직관적으로 이해할 수 있다.
각 layer가 얼마나 많은 전체 network에 대한 이래(collective knowledge)를 가질 것인가를 결정하는 것이 growth rate이다. 즉, growth rate는 각 layer가 전체적인 상태(global state)에 얼마만큼 새로운 정보를 제공할지를 결정하는 요소이다. 기술된 global rate는 모든 layer에서 접근이 가능하다. (concatenate해서 입력으로 받기 때문에)
d. Bottleneck Layer -> 각 layer가 k개의 output feature maps만을 만들어내지만, 일반적으로 그에 비해 더 많은 input을 가지고 있다. 1x1 convolution layer는 3x3 짜리 앞에서 bottleneck layer의 역할을 하게 되는데, 이 bottleneck은 입력되는 feature map의 숫자를 줄여 계산 효율성(computational efficiency)을 높인다. 실험에서는 bottleneck layer를 이용하여 4k feature maps를 만들게 하였다.
d. Compression -> model을 좀 더 압축시키기 위하여, transition layer에 feature map 숫자를 줄일 수 있다. dense block이 m개이 feature map을 가질 때, transition layer는 이보다 더 적은 feature map을 만들게 network를 설계한다.(이 때 압축률(compression factor)이 주어진다) 압축률이 1인 경우 feature map의 숫자는 바뀌지 않는다. 실험에서는 0.5의 압축률을 사용하였다. (여기에 bottleneck이 더해진 모델을 DenseNet - BC라 부른다)
e. 설계 -> (아래 그림 참조)

5. 실험 결과
DenseNet-BC이 성능이 뛰어난 것을 위의 표를 통해 확인할 수 있다.
<Dataset에 대한 설명>
a. CIFAR
색깔을 갖는 32x32 pixel의 image들로 이루어져 있다. CIFAR-10(C10)은 10개의 종류(class)를 구별하고, CIFAR-100(C100)은 100개의 image를 구별한다. 훈련하는 이미지는 총 50000개이고, 테스트하는 이미지는 10000개이다. (그리고 검증(validation)을 위하여 5000개의 image를 이용하였다). standard data augmentation(mirroring/shifting, 즉 이미ㅈ의 변주를 주어서 학습시키는 방법, 반전시키거나 이동시키거나!)을 사용하여서 진행하였다. 이러한 Dataset에는 +를 붙여 표현하였다(C10+, C100+). Preprocessing을 위하여 channel(R, G, B)의 평균과 표준편차를 이용하여 normalize하였다. 마지막 과정에서는 모든 50000개의 데이터를 이용하여 테스트 에러를 기록하였다.
b. SVHN
Street View House Numbers의 약자이다. 32x32 pixel의 RGB 컬러 이미지로 이루어져 있다. 73257개의 훈련 데이터, 26032개의 테스트 데이터, 그리고 531131의 추가 훈련 데이터를 사용하였다. data augmentation을 진행하지 않았으며, validation set을 훈련 데이터에서 6000개를 분리하여 사용하였다. Validation 데이터에 대하여 가장 에러가 작은 model을 골랐으며, 이를 이용하여 test error를 기록하였다. pixel의 각 값들을 255로 나누어, 0 부터 1 사이에 값을 갖게 하였다.
c. ImageNet
ILSVRC 2012 classification 데이터 셋은 120만개의 훈련 데이터, 50000개의 검증 데이터, 1000개의 이미지 종류(class)로 이루어져 있다. data augmentation을 cifar10처럼 적용하였으며, 224 x 224 크기의 single-crop방식이나 10-crop을 테스트를 위하여 사용하였다.
<훈련 과정>
모든 훈련은 SGD(stochastic gradient descent)를 이용하였다. CIFAR, SVHN의 경우 64의 batch size와 40번 반복하였다.(40 epochs). 초기 학습율(learning rate)은 0.1에서 시작하여 50%의 훈련이 진행하였을 때 10으로 한번 나누고, 75%의 훈련이 진행되었을 때 다시 나눴다. ImageNet의 경우에는 90개의 epoch가 256의 batch size, 그리고 30번째, 60번째 epoch에서 10분의 1로 감소하는 학습율(초기값은 0.1)을 사용하였다. Denset의 단순(naive)버전은 메모리적으로 비효율적이기 때문에, GPU의 메모리 사용량을 줄이기 위하여 memory-efficient 버전 역시 언급할 예정이다. Weight decay는 0.0001이고, Nesterov momentum을 0.9만큼 주었다. (감쇠(dampening) 없이). data augmentation을 하지 않는 3개의 데이터셋(C10, C100, SVHN)에 대하여 0.2의 확률을 갖는 dropout layer를 추가하였다.(20%의 확률로 특정 cell을 사용하지 않는다).
<Classification 결과>
Densenet을 다양한 L(깊이)와 k(성장률)에 대하여 훈련을 진행해보았다. 아래 사진 참조.

6. 분석
Densenet은 ResNet과 상당히 유사하다.(단지 각 layer의 input data(function)이 다르다, Resnet은 이전 입력을 더하는 대신, DenseNet은 이전 입력을 평행하게 붙인다(concatenate)). DenseNet의 특징은 다음과 같다.
a. Model의 Compactness
특정 층에서 학습된 feature map들은 그 뒤에 있는 모든 층에서 접근이 가능하다. 따라서, 모든 network를 통하여 feature를 다시 사용하기 용이하게 만들어 model의 compact를 개선하였다. (즉 parameter efficiency가 뛰어나다, 같은 parameter 수를 이용하고도 더 좋은 성능을 낼 수 있다)

위의 그래프를 보면 DenseNet-BC가 parameter를 효율적으로 사용하고 있음이 증명된다.
b. Implicit Deep Supervision
DenseNet의 뛰어난 성능에 관한 또 다른 해석은 개별적인 층들이 shorter connection을 이용하여 추가적인 정보(supervision)을 손실(loss)에서 얻을 수 있다는 것이다. 즉, DenseNet을 deep supervision이라 볼 수 있다. (deeply-supervised nets DSN이라는 모델이 존재한다 -> 모든 layer마다 분류를 진행 -> feature를 구분하는 능력을 배운다). DenseNet은 같은 loss function을 모든 층이 공유하기 때문에 대체적으로 손실함수(loss function)이나 gradient(미분값)이 복잡하지 않다는 장점도 가진다.
c. Stochastic depth
Stochastic depth에서는 각 layer들이 무작위로 사용되지 않는다(randomly dropped). 이러한 특성으로 인해 주변 layer들과 직접적인 연결이 가능해지는데, 이 때 pooling layer는 drop하지 않으므로 DenseNet과 상당히 유사한 연결 패턴을 가진다고 볼 수 있다. 즉 DenseNet을 통해 Stochastice Depth을 기반으로 한 Regularization 관련 통찰력을 얻는 것이 가능할 수 있다.
d. Feature reuse
위에서 언급했던 내용들과 같다.
7. 결론
DenseNet은 뛰어난 성능을 보이는 새로운 CNN 모델이다.
또한 적은 parameter와 적은(less) computation을 통해 좋은 성능을 얻는 등 model compactness 역시 뛰어나다.
Because of their compact internal representations and reduced feature redundancy, DenseNets may be good feature extractors for various computer vision tasks that build on convolutional features
-> 즉 이러한 DenseNet의 장점을 이용한다면, feature을 추출하는 새로운 연구가 가능할 것이다!
저자도 마지막에 feature transfer 등에 대한 연구를 진행해보고 싶다 밝혔다.
(특징적인 부분을(feature) 다른 모델에서 학습시킨 뒤, 새로운 예측을 진행할 때 사용하는(transfer) 방식을 적용하고 싶은 모양이다. model transfer learning의 좀 더 복잡한 과정이라 생각된다)
'컴퓨터비전(CV)' 카테고리의 다른 글
| Swin Transformer (2021) : 새로운 CV 모델의 시작 (0) | 2022.03.06 |
|---|---|
| Mask R-CNN(2017) (0) | 2021.06.06 |
| SENet(2019) (0) | 2021.05.06 |


