
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GAN
- PatchGAN
- self-supervised learning
- PGGAN
- Unsupervised Representation Learning
- xai
- Image-to-image translation
- Latent space
- conditional GAN
- PatchDiscriminator
- pix2pix
- clova
- LSGAN
- Representation learning
- Markov Random field
- Mutual Information
- Unsupervised learning
- Gradien Vanishing
- DCGAN
- StarGAN
- InfoGAN
- Styletransfer
- ICLR
- Computer Vision
- Generative model
- Ian GoodFellow
- Today
- Total
AI with U-Seminar, Daneil Jeong
Temporal Fusion Transformers(2020) 본문
시계열 데이터를 처리하는 가장 SOTA(state of the art) 논문입니다.
논문링크
시퀀스 데이터에 흔히 사용되는 transformer기반으로 여러 통계적 지식들을 적용한 모델입니다.
1. 초록
여러 날을 예측하는(multi-horizon forecasting) 시계열 데이터는 복잡한 입력들의 조합을 종종 포함하는데, 그러한 것들에는 시불변(time-invariant, static) covariates(미래의 입력으로 알려져있다)나 과거에만 관측된 다른 외인성(exogenous) 시계열 특성들(타겟과 어떠한 상호작용을 하는 지 사전 정보가 없는)이 존재한다. 여러 딥러닝 모델들이 제안되었지만, 그들은 대표적인 '블랙박스' 모델들로, 실용적인 상황에서 전체 길이의 입력들이 어떻게 사용되는 지에 대한 통찰을 제공하지 못한다. 이 논문에서는, 새로운 attention 기반 구조와 해석 가능한 인사이트를 담고 있는 TFT(temporal fusion transformer)을 제안한다. (temporal dynamics) 다른 scale들에서 시간 사이의 관계를 학습하기 위해, TFT는 지역적인 처리를 위해 recurrent 층들을, long-term dependency를 위해 해석가능한 self-attention을 이용한다. TFT는 특별한 성분을 이용하여 관련성이 높은 feature들을 선택하고 연속된 gate 층들을 이용하여 불필요한 정보를 차단하여 광범위하게 높은 성능을 낼 수 있다. 여러 존재하는 benchmark들에 대하여 실제 다양한 데이터셋들에서 TFT가 강한 성능과 실용적인 해성가능성을 보여줄 수 있음을 보인다.
2. 서론
Multi-horizon forecasting(여러 미래의 타임 스텝에 대하여 예측을 진행하는 것)은 시계열 머신 러닝에서 중요한 문제이다. 한 스텝 후만을 예측하는 것과 달리, multi-horizon은 유저에게 전체 시계열 데이터에 대한 접근을 가능케하고, 미래의 다양한 스텝들에 대하여 결과를 낼 수 있게 해준다. 이러한 예측은 실생활에서 유통업, 헬스케어, 경제학들에서 중요하게 사용되며 성능 향상은 따라서 매우 가치있는 것이라 할 수 있다.

실제 multi-horizon 예측은 위 그림과 같이 일반적으로 다양한 데이터 소스에 접근하게 된다. (미래에 알고 있는 정보(휴일 날짜), 다른 외인성 시계열 정보(historical 고객의 foot traffic, 아마 고객의 성향? 추세?) 정적인 메타데이터(static metadata, 상점의 위치) 등이 어떠한 사전 지식도 없이 제공된다) 이러한 데이터의 이질성(heterogeneity, 개별연구에서 도출된 결과들의 차이가 우연에 의한 오차보다 큰 것)은 multi-horizon 예측을 어렵게 만든다(사용할 수 있는 정보가 부족하다) DNN들이 많이 사용되곤 하는데, 전통적인 시계열 모델에 비해 탁월한 성능을 보인다. RNN의 변형에 대부분 주목하는 것과 달리, attention 기반에 모델들이 좋은 성능을 보일 수 있음이 최근 입증되고 있다.(Transformer기반) 그러나, 이러한 모델은 간혹 모든 외인성 입력들이 미래에도 알 수 있다는 가정이나(autoregressive 모델의 대표적인 단점), 동적인 covariates를 무시하거나(time-dependent feature들과 단순하게 결합된다) 하는 등의 이유로 multi-horizon의 다양한 종류의 입력들을 고려하는 데 실패한다. 최근 많은 개선된 모델들은 데이터의 고유한 특성을 구조적으로 정렬함으로 좋은 성과를 얻어냈다. 현재 대부분의 모델들은 '블랙박스' 모델들로, 예측들이 많은 parameter들 사이에 복잡한 비선형적인 상호작용에 의해 결정된다. 이는 모델들이 예측을 어떻게 만들어냈는 지 알기 어렵게 만들며, 유저들이 모델의 출력을 신뢰하거나 디버깅하게 힘들게 한다. 불행히도, 일반적으로 사용되는 설명가능한 DNN 모델들은 시계열에 적합하지 않다. convolution 기반의 post-hoc 기법(LIME, SHAP)은 입력 feature의 시간 순서를 고려하지 않는다. LIME의 경우 각 데이터 포인트마다 독립적으로 모델들이 만들어지고, SHAP의 경우에는 feature들이 근접한 타임 스텝과 독립적으로 고려된다. 이러한 post-hoc 접근들은 시계열 데이터에서 중요한 시간대에 따른 상관관계(dependency)를 설명하는 능력이 부족하다. 반면, 어떠한 attention 기반의 구조들은 시퀀스 데이터에 대한 해석력이 뛰어나다(기본적으로 언어나 스피치). 시계열 데이터에는 다양한 종류의 입력 feature들이 있다는 것이 차이점인데, 고전적인 방법으로는 이러한 구조들이 multi-horizon 예측에서 시간대 사이의 상관관계에 대한 통찰을 제공할 수 있지만, 주어진 타임스텝에 따른 feature들의 각각의 중요성을 구분하기 힘들다. 따라서, 새로운 기법은 이러한 예측이 해석가능하게 만드는 것이 필수적이다.
attention 기반의 DNN 구조인 TFT는 새로운 해석력을 제공한다. 잠재적인 입력들과 시간적인 관계를 정렬하기 위해 다양한 혁신적인 생각들을 사용한다. specifically incoporating(통합), 정적인 covariate 인코더(context 벡터를 인코딩), 불필요한 정보를 최소화하는 gating 기법, seq-to-seq 층(알고 있는, 또는 관측된 입력을 처리하는), temporal self-attention decoder(long-term dependency 학습). TFT는 3개의 해석가능한 귀중한 관측을 제공하는 데, globally 중요한 변수들, 영구적인 시간 패턴, 중요한 사건이다. 실제 다양한 데이터셋들을 이용하여 TFT가 어떻게 실용적으로 적용될 수 있는지 알아보도록 한다.
3. 관련지식
Multi-horizon 예측에 사용되는 DNN들 : autoregressive 모델들과, seq-to-seq 모델로 나뉜다. 반복 접근의 경우에는 한 시점 뒤의 예측을 이용한다(얻은 결과를 반복하여 feed해줘(미래의 입력으로 사용하여) 최종 출력을 구한다). LSTM 네트워크(Deep AR, stacked LSTM을 이용) DSSM(Deep State-Space Model) 등이 존재한다. 최근에는, Transformer 기반에 구조들이 예측 시 receptive 영역을 늘리기 위해 지역적인 처리를 하는 convolution과 sparse attention을 같이 사용한다. 이러한 단순함에도 불구하고, iterative 기법들은 모든 변수들을 미래에도 알 수 있다는 가정에 기반한다(타겟은 오롯이 미래의 입력을 반복적으로 feed하면 된다). 그러나, 실제 여러 상황에서는 여러 유용한 시간에 따른 입력들이 존재하며, 이는 사전에 알기 어렵다. 그렇기 때문에 직접적인 사용에 제한이 있는데, TFT의 경우 다양한 입력값(정적인 covariates나 시간에 따른 입력)을 다룰 수 있다. 반면, direct 기법의 경우에는 여러 horizon에 대한 값을 한번에 출력하도록 훈련된다. 이러한 모델들은 일반적으로 seq-to-seq 모델을 기반으로 한다.(LSTM 인코더를 이용하여 과거의 입력을 요약하고, 미래의 예측을 다양한 기법을 사용하여 만들어낸다). MQRNN(Multi-horizon Quantile Recurrent Forecaster)는 LSTM이나 conv 인코더를 이용하여 context 벡터를 만들고, 이를 각각의 horizon에 대하여 MLP(다층 퍼셉트론)에 feed하였다. multi-model attention 기법은 LSTM 인코더을 이용하여 context 벡터들 만들고 bi-directional LSTM을 decoder로 사용하였다. LSTM iterative 기법들보다는 좋은 성능을 갖고 있으나, 해석력은 여전히 문제점이 된다. 이와 달리, TFT는 attetnion의 패턴을 해석하여 시간적 역동성에 대한 통찰력 있는 설명이 가능하다.
Attention의 시계열 해석력 : attention 기법은 번역, 이미지 분류, 표의 학습(tabular learning) 등에서 attention 가중치를 이용하여 각각의 입력의 영향력을 알 수 있게 해준다. 최근에는, 시계열에서 해석력을 위해 사용되는데, LSTM이나 transformer 기반의 구조에서 주로 사용한다. 그러나 이들은 정적 공변량(covariate)의 중요성을 고려하지 못한다. TFT는 이러한 문제를 정적 feature들에 대하여 개별적인 encoder-decoder attention을 사용함으로 해결하고자 한다.
4. Multi-horizon Forecasting
주어진 시계열 데이터셋에 대하여 다양한 상점들이나 헬스케어에서 고객들과 같이 고유한 객체 I가 존재한다 하자. 각 객체 i는 정적 공변량의 집합과 연관되어 있다. 시간에 의존적인 입력 feature들은 두 개의 카테고리로 나뉘게 되는데, 하나는 관측값이고(각 시점에만 측정됨, 즉 이전에는 알 수 없음), 나머지는 알려진(known) 값들이다(이미 결정되어 있음, 요일 등이 이에 해당됨). 여러 상황에서, qunatile regression을 사용하여 예측을 진행한다. (Quantile은 분위수를 의미하는데, 여기서 10th, 50th, 90th percentiles를 사용하겠다 한다, 즉 자료를 100등분하여(percentile)하였을 때 해당되는 값이다, 50 percentile은 median(중앙값)을 의미하게 된다) 각 quantile 예측은 다음과 같은 형태를 지닌다.

이 때 y는 q번째 sample quantile에 대하여 t 시점에서 타우번째 뒤에 해당하는 예측에 해당하며, f는 예측 모델이다. k의 look-back window를 이용하여, 시작하는 지점인 t로부터 k개 이전까지의 값들을 이용한다.

TFT의 주요 구성 성분은 아래와 같다.
1. Gating 기법 : 이를 통해 사용되지 않는 성분을 skip한다. adaptive depth와 network complexity를 통해 광범위한 데이터셋을 다룰 수 있다.
2. Variable Selection 네트워크 : 관련 있는 입력 변수들만 선택한다
3. Static covariate encoder : 정적 공변량들을 context 벡터를 인코딩함으로 네트워크에 합친다
4. Temporal processing : 장기, 단기 시간 관계를 학습한다. 관측 입력과 알고 있는 입력들에 대하여 모두 진행한다. seq-to-seq 층은 local processing에 사용된다. multi-head attention을 이용하여 장기 의존성을 알아낸다.
5. Prediction intervals : 타겟 값들의 적절한 범위를 결정한다(quantile을 이요하여)
<자세한 설명>
1. Gating 기법
외인성 입력들과 타겟 사이의 정확한 관계는 종종 미리 알 수 없어 어떠한 변수들이 연관되어 있는지 예측하기 힘들게 만든다. 더욱이, 필요되는 비선형 처리의 길이를 결정하기 힘들며 단순한 모델들이 훨씬 효과적일 수 있는 작거나 잡음이 심한 데이터셋이 존재하기도 한다. 필요할 때만 비선형 처리를 하여 모델의 유연성을 높이고자, GRN(Gated Residual Network)를 제안한다. 초기 입력 a와 선택적 context 벡터 c를 받아 아래 식과 같이 처리한다.
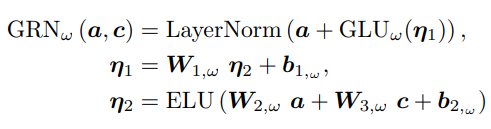
ELU는 Exponential Linear Unit activation 함수를 의미하고, 에타1,2는 모두 중간 층에 해당하며, standard layer normalization을 사용하였으며, 오메가는 weight sharing의 index를 의미한다. ELU는 입력이 0보다 클 때 identity 함수이고, 0보다 작을 때는 일정한 출력을 낸다. GLU(Gated Linear Units)을 사용하여 주어진 데이터셋에서 필요하지 않는 부분을 제거한다. GLU는 다음과 같다.

이 때 시그모이드 활성화 함수가 사용되었다. 연산은 elementwise 아다마르 곱(Hadamard product)을 사용한다. GLU는 TFT에서 a의 비선형 기여도를 바꿀 수 있는데, 예를 들어 GLU의 출력이 모두 0이라면 a의 비선형 기여도는 억압된다.(없는 것과 마찬가지) context 벡터 없이 GRN은 단순히 context 입력을 0이라 간주하게 된다.(c = 0) 훈련 과정에서 gating 층과 layer norm이전에 dropout을 적용한다.(예를 들어 n1에서)
2. 변수 선택
다양한 변수들이 사용가능한 반면, 출력에 대한 그들의 연관성이나 명확한 기여도는 일반적으로 알기 어렵다. TFT는 instance-wise 변수 선택을 진행한다(static covariate와 time-dependent covariate 둘 모두에 대하여)예측에 직결되는 성분을 골라내는 것은 물론, 불필요한 noisy 입력들(성능에 악영향을 끼친다)도 줄일 수 있다. 대부분의 실제 시계열 데이터셋에는 예측과 관련없는 값들이 많으므로, 변수 선택은 모델의 성능 향상에 큰 도움이 된다. 카테고리 변수들에 대하여는 객체 임베딩을, 연속적인 변수들에 대하여는 linear transformation을(dmodel의 차원의 벡터로) 진행한다. 모든 정적인, 과거와 미래의 입력들은 분리된 변수 선택 네트워크를 사용한다. (다른 색깔로 표시하였다) ξ을 각 시점에서의 변형된 입력이라 하고, Ξ를 모든 이전 시점 t에 대한 입력들의 flatten 벡터라 하자. 아래 식과 같다.

c는 static covariate 인코더에서 얻어진다. 각 시점에서 비선형 처리를 위한 추가적인 층이 추가된다.

각자의 GRN에 ξ을 넣어준다. (가중치는 모든 시점 t에 대하여 공유된다). weighted sum을 아래와 같이 구한다.

3. 정적 공변량 인코더
TFT는 정적인 메타데이터의 정보를 통합하기 위해 설게되었다. 개별적인 GRN 인코더를 이용하여 4개의 서로 다른 context vector(cs, ce, cc, ch)를 만든다. 이들은 temporal decoder에서 다양하게 사용된다(정적인 변수들이 중요한 역할을 하는 곳) 자세하게는, cs는 시간 변수를 선택하는 context, cc와 ch는 지역 처리를 위한 시간 변수, ce는 정적인 정보들에 대한 시간 변수들을 의미한다.

4. 해석가능한 Multi-Head Attention
self-attention 기법을 이용하여 장기 관계를 파악한다. transformer 기반의 multi-head attention을 이용하여 해석력을 강화하였다.

A는 normalization 함수에 해당한다. 일반적인 선택은 scaled dot-product attention이다.

여러 head를 각기 다른 representation subspace에서 사용하여 학습 효용성을 개선한다.


다른 값들이 각 head에서 사용되기 때문에, attention 가중치가 단독으로는 특정 feature의 중요성을 나타내는 지표가 되기 어렵다. 따라서 위와 같이 multi-head attention을 수정하여 각 head에서 값들을 공유하게 하였다.

각 head는 다른 시간 pattern을 학습하고, 이들이 입력으로 단순히 ensemble되었다 생각할 수 있다. 이는 representation의 효용력을 효율적으로 증가시킨 결과를 얻어낸다.
5. Temporal Fusion Decoder
여러 층의 연속으로 이루어진다. 시간 관계를 학습하게 한다.
a. Seq-to-seq (지역성을 강화 시킨다)
시계열 데이터에서는 주위 값들 사이의 연관성을 통해 중요도가 결정되곤 한다. local context을 끌어올리는 것은 따라서 attention 기반 모델에서 성능 향상이 가능케 한다. 예를 들어, 1개의 conv 층을 이용하여(모든 시간대에 대하여 동일한 filter 사용, 지역적 패턴 추출) locality를 추출할 수 있다. 그러나 관측 데이터가 있을 때는 적합하지 않다. (과거와 미래 입력의 숫자가 다르기 때문). 이 차이를 해결하기 위해 t-k~t를 인코더에, t+1~t+tmax를 디코더에 넣어준다. LSTM 인코더와 디코더를 사용했으며, 다른 모델 역시 사용 가능할 것이다. 이는 positional 인코딩을 대신하는 효과도 있는데, 시간 순서에 대한 적절한 inductive bias를 제공해주기 때문이다. 더욱이, 정적 메타데이터를 이용하기 위해, cc와 ch context 벡터들을 사용한다.(이들이 cell state와 hidden state의 초기값이 된다). gated skip connection도 사용하였다.

b. static enrichment layer
정적 공변량의 영향력이 상당한 경우가 있기 때문에, static enrichment 층을 이용하여 이러한 static 메타데이터의 시간 feature들을 강화한다. 각 위치 n에 대하여 아래와 같다.

GRN의 가중치들은 모든 층에서 공유된다, ce는 context 벡터에 해당한다.
c. temporal self-attention 층
static enrichment에 이어서, self-attention을 적용한다.

d. position-wise feed-foward layer
6. Quantile outputs

'데이터사이언스' 카테고리의 다른 글
| N-Beats(2020) 정리 (0) | 2021.04.20 |
|---|
