
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- PatchDiscriminator
- PatchGAN
- Unsupervised learning
- pix2pix
- Styletransfer
- GAN
- xai
- self-supervised learning
- clova
- PGGAN
- Computer Vision
- Markov Random field
- Ian GoodFellow
- Gradien Vanishing
- Generative model
- conditional GAN
- ICLR
- LSGAN
- Image-to-image translation
- Mutual Information
- Representation learning
- InfoGAN
- Unsupervised Representation Learning
- DCGAN
- StarGAN
- Latent space
- Today
- Total
AI with U-Seminar, Daneil Jeong
Generative Adversarial Nets (2014) 본문
GAN 논문 리뷰 첫번째입니다.
0. 배경
Generative Model은 초기 Boltzman machine으로 부터 시작하여 DBM(2009), VAE(2014)등이 등장하였습니다.
Generative Model을 2개의 큰 특징으로 정의하면 아래와 같습니다.
- Generative model can generate new data instance.
- Generative model capture the joint probablity.
두 말을 종합해보면, 생성 모델은 새로운 데이터의 집합을 만들어내는 데, 이 때 만들어진 데이터의 집합은 훈련 데이터의 distribution을 따르려고 합니다.
GAN에 대한 설명에 앞서 GAN과 가장 많이 비교가 되는 모델인 VAE를 간략히 설명하고자 합니다.
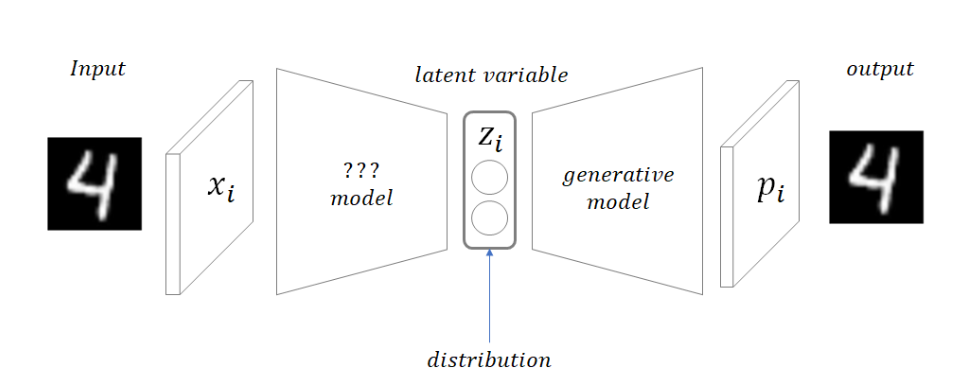
위 그림과 같이 VAE는 encoder와 decoder의 구조로 이루어집니다.
인코더는 임의의 샘플로부터 latent variable을 뽑아내고, 디코더는 뽑아낸 latent를 활용하여 이미지를 다시 만들어냅니다. 찾고자하는 latent의 space가 manifold형태로 샘플 별로 잘 나누어지도록 만드는 것이 VAE의 목표입니다.
2014년에 나온 GAN의 경우 encoder가 없이 decoder인 generator만을 사용합니다.
이러한 generator의 적대적인 discriminator를 사용하기 때문에 Adversarial network라 불립니다.
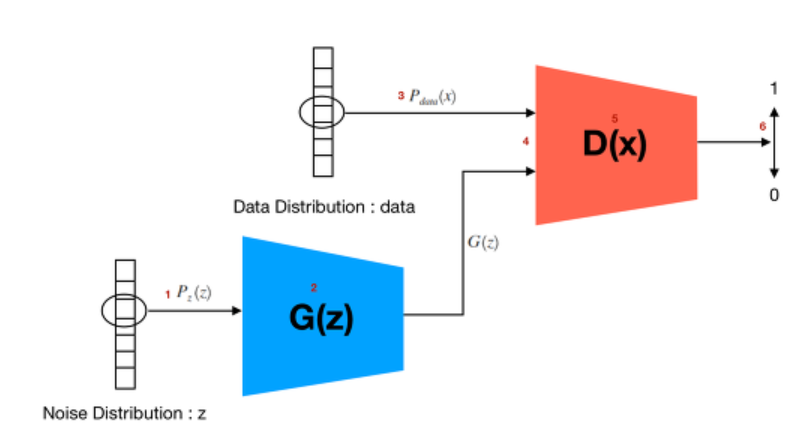
GAN의 목표는 좀 더 확고합니다. 시작점을 임의의 normal distribution(gaussian)의 noise로부터 시작하여, 실제 데이터셋의 latent space(잠재공간)을 찾고자 합니다. 이러한 목표를 달성하기 위해 generator와 discriminator는 일종의 시합을 진행하게 됩니다.
1. GAN 논문 읽기
논문 주소 : https://arxiv.org/abs/1406.2661v1
Generative Adversarial Networks
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that
arxiv.org
GAN의 핵심은 두 개의 적대적인 모델을 사용하는 데 있습니다. 아래 가로 안의 예시는 실제 논문의 저자가 든 예시입니다.
- 생성 모델 G는 훈련 데이터의 distribution을 알아내기 위해 노력합니다. (위조 지폐범)
- 적대적 모델 D는 G가 만들어내는 가짜 데이터를 판별하기 위해 노력합니다. (경찰)
두 개의 서로 다른 적대적 모델은 게임을 하게 됩니다. Generator는 Discriminator를 속이기 위해 노력합니다(maximize the probabilty of D making a mistake). 즉 진짜와 구분될 수 없는 수준의 가짜 데이터를 만들기 위해 노력합니다. 이 과정에서 데이터의 distribution에 이상적으로 일치하게 되는 latent space를 찾을 수 있게 됩니다. Discriminator는 진짜와 가짜 샘플을 완벽히 구분하기 위해 노력합니다(minimize the probabiltiy of D making a mistake). 즉, 임의의 함수(모델) G와 D는 maximize와 minimize를 동시에 진행하는 minimax game을 통해 학습을 진행합니다.
(실제 식에서는 D가 올바른 판별을 할 확률을 높이고(max), G(z)의 distribution이 data와의 차이를 줄여야(min)하기 때문에 min max가 반대로 됩니다)
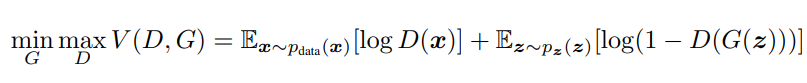
두 함수는 이상적으로 unique solution을 갖을 수 있습니다. (G가 trainining data distribution을 완벽히 구해내고, D는 real과 fake를 완벽히 구분함(하지만 fake sample과 real sample을 구분할 수 없으므로 50%의 확률로 fake를 판별함))
논문에서는 간단한 MLP로 두 모델을 구성하였고, backpropagation을 이용하여 목적 함수를 학습합니다.
min max game의 식에서, 입력인 noise는 prior이 됩니다. noise z는 parametric function G를 이용하여 mapping되는 데, 이 때 data sample space가 되도록 G를 학습시킵니다. D의 경우 주어진 데이터가 real인지 판단하는 probability로, single scalar 출력을 갖습니다.
a log(y) + b log(1-y) 의 함수를 미분해보면, y가 a/a+b인 지점에서 최댓값을 갖는 것을 알 수 있습니다. ([0, 1])
이는 목표를 이룬 최적의(optimal) D의 형태와 같다는 것을 알 수 있습니다. 물론 위의 value 함수 V에서는 G라는 방해꾼이 있어서 목적을 달성하는 데 어려움이 많습니다.
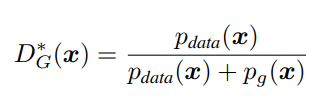
이를 이용해서 training crieterion C(G)를 새로 정의해봅시다.

C(G)의 global minimum은 p_g = p_data 일 때(D의 값이 0.5가 될 때)만 가능해집니다. (그 때의 값은 -log4)
위와 같은 성질을 이용하여 Kullback-Leibler의 개념을 도입하면,
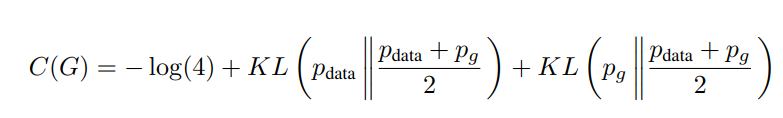
C 함수는 위와 같이 새롭게 바뀌게 됩니다. (KL Divergence는 두 distribution 사이의 차이를 구하는 정보 이론의 방법입니다. 위 식을 해석해보면, 두 data distribution의 평균이 각각의 distribution과 얼마나 비슷한 지를 보는 것이 됩니다. 여기서 divergence는 상대 엔트로피(relative entropy), 정보 획득량(information gain)으로 불리기도 합니다.
논문에 나온 그림과 같이 다시 한번 확인해보겠습니다.

위 그림에서 점선이 실제 데이터의 분포, 초록색 선이 생성 모델의 데이터의 분포를 의미합니다. 맨 아래 수평선은 z가 샘플링 되는 domian이고, 그 위는 x의 domain입니다. z의 mapping x=G(z)가 학습이 진행될 수록 high density한 data distribution을 찾게 되는 것을 확인할 수 있습니다. 초기 학습에서는 log(1-D(G(z))가 saturate될 확률이 높습니다(G가 잘 작동하지 않기 때문에)). 이 때 log(D(G(Z))를 높이는 방향으로 G를 학습하여 이러한 상황을 벗어날 수 있습니다. 즉, D의 학습은 G가 어떠한 방향으로 학습을 진행해야 하는 지 알려주는 이정표의 역할이 됩니다.
2. GAN의 문제점
초기 GAN의 가장 큰 문제점은 4가지 정도로 요약해볼 수 있습니다.
- latent를 표현할 수 있는 explicit representation이 없다
- 훈련 과정이 instable하다 (G와 D가 한쪽에만 치우치게 학습할 위험이 큼)
- Helvetica scenario (G가 discriminator를 속이기 위해 특정 mode만을 이용하여 다양성이 감소됨, mode collapse)
- 평가 지표가 마땅히 없다
각각에 대해서 어떠한 논문들이나 아이디어가 등장할 수 있었을 까요?
지금 선에서 유추할 수 있는 것들은 아래 정도일 거 같습니다.
- latent를 만들어내는 encoder를 같이 학습시킬 수 없을까?
- 다양한 Discriminator 혹은 Generator를 사용하여 학습을 안정화시켜볼까?
- 새로운 loss function을 고안하여 stable한 학습을 진행해볼까?
- 통계학적인 지표를 고려한 평가 지표를 만들어볼까?
- 라벨링을 해서 conditional하게 generative를 해볼까?
이 외에도 다양한 생각을 해보시며 다음 GAN 모델들을 접하면 좋을 거 같습니다.
3. 결론
GAN의 가능성에 대한 고찰이 담긴 논문입니다. 생성 모델을 넘어 다양한 분야에 사용되고 있는 GAN의 시초인 논문으로, 리뷰를 하는 2022년에 봐도 굉장히 잘 쓰여진 논문입니다. 8-9쪽에 아래와 같은 future work에 대한 논의를 적어놨는데, GAN의 확정성에 대해 고민해보기 좋은 거 같은 글입니다.


'GAN' 카테고리의 다른 글
| Pix2Pix(PatchGAN, 2016) (0) | 2022.04.23 |
|---|---|
| LSGAN (2016) (0) | 2022.04.22 |
| Wasserstein GAN (2017), WGAN-GP (0) | 2022.04.21 |
| InfoGAN (2016) (0) | 2022.04.18 |
| DCGAN (2015) (0) | 2022.04.15 |



