
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- ICLR
- DCGAN
- PatchDiscriminator
- Ian GoodFellow
- StarGAN
- Representation learning
- GAN
- Markov Random field
- Gradien Vanishing
- PatchGAN
- Unsupervised Representation Learning
- Computer Vision
- pix2pix
- Generative model
- PGGAN
- Mutual Information
- LSGAN
- Unsupervised learning
- xai
- Latent space
- clova
- Image-to-image translation
- InfoGAN
- Styletransfer
- conditional GAN
- self-supervised learning
- Today
- Total
AI with U-Seminar, Daneil Jeong
InfoGAN (2016) 본문
최초의 GAN이 2014년에 나온 뒤 여러 generative model들에 대한 연구가 쏟아졌습니다.
GAN은 임의의 noise(latent variable)로부터 원하는 샘플을 만들어낼 수 있는, 즉 타겟 데이터셋의 분포를 완벽히 표현할 수 있는 잠재공간(latent space)를 찾고자 하는 생성 모델입니다.
아래는 GAN에 대한 설명입니다.
https://aijyh0725.tistory.com/12
Generative Adversarial Nets (2014)
GAN 논문 리뷰 첫번째입니다. 0. 배경 Generative Model은 초기 Boltzman machine으로 부터 시작하여 DBM(2009), VAE(2014)등이 등장하였습니다. Generative Model을 2개의 큰 특징으로 정의하면 아래와 같습니다...
aijyh0725.tistory.com
Generative model에는 GAN외에도 VAE 등이 존재하였는데, 그 중에서도 GAN에 적절한 NN(neural network)와 objective를 이용하여 학습시키는 방법에 대한 연구가 많이 진행됩니다.
특히나 computer vision 분야에서 큰 힘을 발휘하던 convolutional 뉴럴 네트워크를 이용한 방법이 등장하였는데요,
아래 사이트에서 볼 수 있는 것과 같이 DCGAN을 통해 안정적인 훈련과 unsupervised representaiton learning이 가능하다고 주장합니다.
https://aijyh0725.tistory.com/13
DCGAN (2015)
GAN 2번째 논문입니다. 이전글에서는 GAN을 소개하였습니다. https://aijyh0725.tistory.com/12 Generative Adversarial Nets (2014) GAN 논문 리뷰 첫번째입니다. 0. 배경 Generative Model은 초기 Boltzman mach..
aijyh0725.tistory.com
그런데, DCGAN에는 몇가지 문제점들이 존재합니다. 먼저 disentangled representation이 정확히 어느 latent에 해당되는 는지 알기 어렵습니다. 좀 더 자세히 말하자면, DCGAN에서의 disentangled representation들의 발견은 순전히 우연에 지나지 않습니다. semantic한 control을 위한 정확한 목적이나 방향도 부족했고(objective의 한계), 또한 단순히 noise를 generator에 넣은 뒤 구해지는 각 layer의 feature representation에 대한 탐구에 그쳤습니다. 즉, 이용하고자 하는 latent의 특징이 불분명하다는 것입니다.

여기까지 글을 읽었을 때, InfoGAN이 하고자하는 것을 대충 눈치채신 분도 있을 것입니다. 원하는 disentangled한 semantic을 표현하는 latent code를 구하기 위해 명확한 목표를 잡는 것이 InfoGAN의 목표입니다.
InfoGAN의 키워드는 다음과 같이 요약할 수 있습니다.
- Information theory - Maximize the mutual information
- latent code - disentangled representation
- interpretable representation
latent code와 mutual information. 벌써부터 어려운 용어들이 쏟아지는 데요. 아이디어와 실제 모델 자체는 굉장히 단순한 편입니다 (그래서 매력적입니다) 간단한 논문 리뷰와 함께 확인해보겠습니다.
https://arxiv.org/abs/1606.03657v1
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
This paper describes InfoGAN, an information-theoretic extension to the Generative Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner. InfoGAN is a generative adversarial network that also maximizes t
arxiv.org
1. 논문 리뷰
이 당시 사용되는 생성 모델들은 unsupervised learning의 주요 연구 분야였습니다. 그리고, 좋은 학습 모델은 분명 자동적으로 disentangled representation을 학습할 것이라 믿었죠. 여기서 disentangled의 의미는, 특정 representation이 vector space상에 존재할 때, 그 representation의 다양한 semantic 정보들이 얽혀있지 않아(disentangled) 특정 방향(basis의 direction)으로 이동이 다른 semantic에 영향을 주지 않는 것을 말합니다.
하지만, 사실 많은 GAN 모델들은 위와 같은 disentaglement을 제대로 수행하지 못합니다. 정확히 말하자면, 논문에서는 적절한 objective와 목적이 없었기 때문이라 주장합니다. 그래서, 논문은 GAN objective에 새로운 term을 추가합니다.
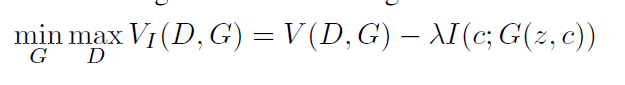
I라는 function이 추가되었는 데, 이 I는 mutual information을 최대화(maximize)하는 역할을 합니다. 이 때 mutual의 기준이 되는 두 공간은 noise variable의 작은 subset(fixed small subset)과 실제 데이터입니다. 이러한 mutual information을 최대화하는 간단한 방법으로, InfoGAN은 semantic하고 의미있는 hidden representation을 찾아냅니다. 기존 방식이 supervised한 방법이었던 것을 넘어서, 심지어 unsupervised한 방법으로 말입니다.

latent code와 mutual information에 관련하여 아래와 같이 한 문장으로 요약합니다.
"the information in the latent code c should not be lost in the generation process"
즉, 생성 과정에서 c가 중요한 정보들을 기억하길 바랍니다. 왜 이런 말을 하였을까요?
기존 GAN의 경우를 먼저 생각해보겠습니다. continuous한 noise 벡터 z의 각 dimension은 사실 별다른 의미를 갖지 않습니다. z의 dimension들은 사실상 entangle하게 generator에 의해 사용됩니다. 하지만 여러 도메인의 데이터들은 사실 continuous한 semantic 정보(e.g. rotation)를 갖기도, 혹은 discrete한 representation을(e.g. MNIST에서의 숫자들) 갖기도 합니다. 그렇다면 이러한 정보들을 표현하는 random variable을 설정해보는 것은 어떨까요? 입력에 사용되는 noise vector를 2개의 파트로 나눕니다. 먼저 더이상 압축할 수 없는(incompressible noise) z와 데이터 분포의 semantic한 feature들을 표현하는 latent code c로 말입니다.
z -> z, c
각 latent code c는 다음과 같이 정의할 수 있습니다.
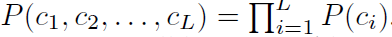
편의를 위해 c가 각 latent code들을 모두 붙인 형태라 하겠습니다 (concatenate)
새로운 generator는 G(z, c)라 표현할 수 있습니다. 기존 GAN의 경우 laten code c가 쉽게 무시되게 학습될 것이며, 따라서 구하고자 하는 generator의 distribution은 c와 무관하게 P(x)로 표현될 것입니다.
InfoGAN은 c가 generator의 distribution에 관여하길 원합니다. 즉, c의 information이 generator의 distribution에서도 유지되길 원합니다. 즉, 둘 사이에 high mutual information이 목적이 되고, 이것이 바로 정보 이론 관점에서 regularizer로 작용하게 됩니다.
mutual information I 함수는 아래와 같이 엔트로피를 이용하여 정의합니다.

직관적으로, mutual information이라 X의 불확실성에서 Y가 관측됨으로 인해 오는 불확실성을 빼주는 것을 의미합니다. 만약 X와 Y가 independent한 random variable이라면 mutual information은 0이 되고, X와 Y가 deterministic, invertible한 함수로 연관되어 있다면 mutual information은 최대가 됩니다.
mutual information을 최대화하는 방법은 사실 실용적으로 굉장히 어렵습니다. 그 이유는 posterior인 P(c|x)의 정보를 알아야하기 때문입니다(일반적으로 사전에 알 수 없습니다). 따라서, 보통 auxiliary distribution Q를 이용하여 Q(c|x)를 근사시킵니다. Q(c|x)를 이용하여 lower bound를 찾을 수 있고, 이를 Variational Information Maximization이라 합니다.

위 식에서 만약 Q가 P에 완벽히 근사한다면, lower bound에 도달하게 됩니다. discrete latent code에서는 lower bound의 최대값을 H(c)로 단순히 구할 수 있고, 이것이 maximal mutual information이 되게 됩니다.
2. 구현
auxiliary distribution Q를 neural network로 parametrize해줍니다. Q는 D와 모든 convolutional layer를 공유하고, 마지막에 FC layer 하나가 output을 구하기 위해 사용됩니다 (conditional distribution Q(c|x)를 구하기 위해)

categorical latent code c에 대해서는 softmax를 이용하여 Q(c|x)를 표현하고,
continuous의 경우에는 true posterior P에 따라 다양한 옵션들을 부여합니다.
추가된 lambda의 경우에는 간단하게 1로 맞추어 discrete latent code를 구하고, 그 외의 경우에는 작은 값을 유지합니다. DC-GAN을 base로 하여 안정적으로 훈련하였습니다.
3. 결론
간단한 objective function을 바꿈으로 좋은 결과를 얻었습니다. 그 외에도 latent code를 다루는 방법론들을 제시하며 GAN 연구의 새로운 지평을 연듯 합니다. 하지만 여전히 문제점들은 많이 존재합니다. 어떠한 latent code를 어떻게 다뤄야 할지 인간의 직관이 많이 필요하고(unsupervised임에도 불구하고), 또한 representation은 여전히 disentangle하다 보기 어렵습니다. 고차원의 데이터를 처리하지 못하는 GAN의 고질적인 문제점들은 반복되고 있었으며, latent representation을 계층적으로(hirerarchical) 분석하는 것도 필요해보입니다.
objective를 정보 이론 관점에서 바꿔보는 것은 굉장히 흥미로운 시도입니다. 특히나 좋은 latent representation과 안정적인 훈련을 위해 적절한 objective의 설정은 이후로도 많이 연구되었습니다.
다음 논문은 새로운 정보이론적 관점을 제시한 WGAN으로 찾아오겠습니다.
'GAN' 카테고리의 다른 글
| Pix2Pix(PatchGAN, 2016) (0) | 2022.04.23 |
|---|---|
| LSGAN (2016) (0) | 2022.04.22 |
| Wasserstein GAN (2017), WGAN-GP (0) | 2022.04.21 |
| DCGAN (2015) (0) | 2022.04.15 |
| Generative Adversarial Nets (2014) (0) | 2022.04.14 |



