
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- pix2pix
- Unsupervised Representation Learning
- DCGAN
- Image-to-image translation
- Unsupervised learning
- conditional GAN
- PatchGAN
- Computer Vision
- self-supervised learning
- GAN
- Styletransfer
- Markov Random field
- ICLR
- Ian GoodFellow
- Mutual Information
- Generative model
- xai
- PGGAN
- LSGAN
- InfoGAN
- StarGAN
- clova
- Gradien Vanishing
- PatchDiscriminator
- Latent space
- Representation learning
- Today
- Total
AI with U-Seminar, Daneil Jeong
Pix2Pix(PatchGAN, 2016) 본문
Computer vision task 중에는 image를 또 다른 image로 바꾸는 task가 존재합니다.

위와 같이 어떠한 input 이미지를 이용하여 output 이미지를 만들어내는 것을 img-to-img translation, 혹은 style transfer 등으로 부릅니다. 특히, input 이미지를 이용하였기 때문에 input에 conditional한 output을 만들어낸다고 표현할 수 있겠습니다.
사용할 수 있는 이미지는 위 그림과 같이 다양하게 존재합니다. 실제 RGB 이미지일 수도 있고, graphical 이미지, edge map, sketch 등등 수많은 옵션들이 존재할 것입니다. 그 중, 현대 사회에서 산업적으로도 많이 사용되는 것은 아마도 흑백사진의 컬러화와, super resolution이라 불리는 저해상도 사진의 고해상도화 일 것입니다.
CNN 등이 컴퓨터 비전에서 많이 사용되었는 데, 이러한 CNN은 image translation task에서 주로 L2 loss 같은 euclidean distance 기반의 방법론들을 사용하여 학습을 진행합니다. 하지만 이러한 Euclidean의 경우 결과값을 averaging하여 비교하고 이를 기반으로 학습하기 때문에 blur된 결과(흐릿한 결과)를 얻는 단점이 있습니다.
논문에서는 이미지 생성에서 강한 성능을 보이던 GAN을 사용하고자 합니다. GAN과 특별한 목적함수(objective)를 이용하여 sharp하고 realistic한 결과를 얻고자 합니다. 그리고 input image를 이용하여 진행하기 때문에, 특별히 conditional GAN이라 이름 붙이고자 합니다. 그렇다면 Pix2Pix 논문은 어떠한 structured loss를 사용하여 문제를 해결하였을까요?
논문 링크
https://arxiv.org/abs/1611.07004v3
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org
GAN 논문 리뷰
https://aijyh0725.tistory.com/12
Generative Adversarial Nets (2014)
GAN 논문 리뷰 첫번째입니다. 0. 배경 Generative Model은 초기 Boltzman machine으로 부터 시작하여 DBM(2009), VAE(2014)등이 등장하였습니다. Generative Model을 2개의 큰 특징으로 정의하면 아래와 같습니다...
aijyh0725.tistory.com
1. 논문 리뷰
Conditional GAN인 pix2pix 모델은, U-Net 기반의 Generator와 PatchGAN이라 명명한 Discriminator를 사용합니다. 그리고 conditional하기 때문에, input x에 대하여 출력 y를 다음과 같이 표현합니다.
G : {x, z} -> {y}
U-Net과 PatchGAN이라는 두 용어가 등장하였습니다.
먼저 U-Net부터 살펴보도록 하죠.

U-Net은 위와 같은 구조로, x를 encoding하고 y를 decoding하는 형태입니다. 그 중에서도 중간에 bottlneck layer가 존재하는 것이 눈에 띕니다. 이 bottleneck에서 low-level information을 x와 y에서 주고받으며 적절한 관계를 학습할 수 있다는 것이 U-Net 모델의 핵심입니다.
그러나, image translation에서 약간의 문제가 발생합니다. image에는 해상도가 존재하고, 또 part-whole 등의 관계 역시 존재하기 때문에 단순히 low-level만을 이용한 소통으로는 좋은 결과물을 얻기 힘듭니다. 과장되거나 뭉개진(blur) 혹은 현실적이지 못한 출력물을 얻을 위험성이 높은 것이죠. 따라서 pix2pix는 각 layer들을 skip-connection으로 연결합니다. 즉, encoder와 decoder에서 같은 해상도를 볼 수 있는 layer들 사이에 정보를 이어주는 작업입니다.
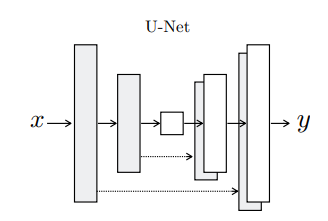
위와 같은 작업을 통해 spatial한 정보들, local한 정보들을 입력과 출력 사이에서 잘 소통할 수 있게 해줍니다. 굉장히 추상적으로 표현하였지만, 이러한 skip connection은 근래(2021년-2022년)에도 많이 사용되는 아주 효과적인 방식입니다.
다음은 PatchGAN의 도입입니다. patch라는 말에서 알 수 있듯이, G가 만들어낸 fake sample을 patch로 나눈 뒤 각 patch에 대하여 fake/real을 판별해줍니다(classifier). 이미지에서는 locality를 강조하기 때문에(즉 주변 pixel에 의해서만 영향을 받을 확률이 크다), 각 patch 별로 일종의 markov random field를 가정하게 됩니다. patch 이외의 픽셀들과는 independent하다고 가정하는 것이지요. 이러한 가정을 토대로, 각 patch들이 얼마나 진짜 같을 지에 대하여 Dicriminator가 판단하게 됩니다. 각 patch 별로 discriminator가 생기는 셈이지요. 이러한 PatchGAN 방식은 texture/stlye loss를 구하던 것과 비슷하게, 이미지 자체의 style을 입력과 출력 사이에서 잘 전달할 수 있는 방법론이 됩니다.
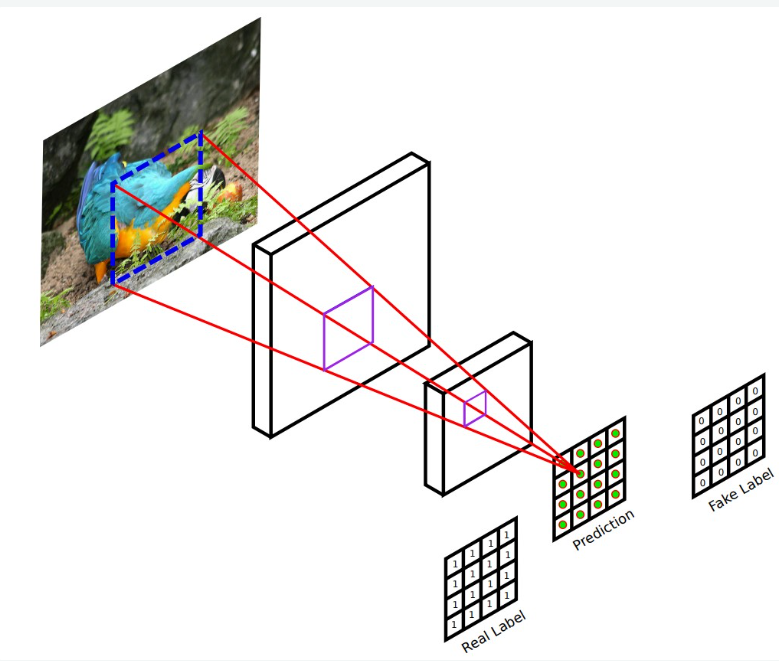
이와 같은 새로운 G와 D를 이용하여 새롭게 구성된 objective를 이용하여 학습을 진행합니다.
우선, 기존 GAN의 objective에 단순히 conditional x를 더한 loss입니다.
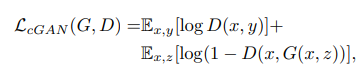
위와 같은 loss에 더하여 L1 loss를 사용합니다. L1 distance는 L2와 마찬가지로 blurring 등의 단점이 있지만 그러한 것이 좀 덜하고(제곱이 없기 때문에), 좀 더 output에 가까운 출력을 얻어내기 위하여 사용합니다. 일종의 penalize로 작용하고 있는 셈이죠. 두 loss를 정리하면 아래와 같이 됩니다.
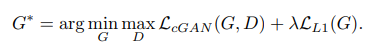
일반적으로 L1 loss를 low frequency 성분들에 영향을 미치므로, local한 Patch Discriminator를 사용하여 high frequency 특징을 만족해줍니다. 학습이 진행될 때 우선 D를 학습하고 G를 학습해줍니다. 이 때, 1 - D(x, G(x,z))를 최소화하는 방식이 아닌, D(x, G(x,z))를 최대화하는 방식으로 G를 효과적이고 안정적으로 학습해줍니다.
L1 loss function은 적절한 penalizer이지만 동시에 blurring이라는 안좋은 단점을 갖고 있습니다. 이를 D를 이용하여 어느 정도 상쇄가 가능하다고 주장하나 확실히 그런지는 모르겠습니다. 그 외에도 L1 loss 등을 이용하여 artifact 등을 제거할 수 있고, input과 output 사이의 현실적인 이미지 생성을 추구할 수 있는 장점을 갖습니다.
논문에서 patch size를 1로 시도한, 즉 PixelGAN 형태로 실험을 진행해보기도 하였는데 colorfulness에 굉장히 효과적이었다고 합니다. 아마도, pixel 단위로 봤기 때문에 좋은 결과물보다는 실제 pixel값들에 좀 더 예민하게 반응해서 그랬던 것 같습니다. patch size로는 70x70이 가장 효과적이고 안정적인 결과물을 만들었다고 합니다.
conditional GAN은 복잡한 이미지, 혹은 photograpic 이미지에 어울리는 작업이라고 합니다.
* 잡담
Patch Discriminator 아이디어는 굉장히 매력적입니다. 사실 이 논문 이후에도 자주 사용되는 아이디어 중 하나입니다. 다만, objective function 쪽이 굉장히 빈약한 듯합니다. 2016년임을 감안한다면 어느 정도 이해될 만한 수준이기 합니다. 그 외에도 논문을 실제로 보시면 결과물이 생각보다 엄청 좋진 않습니다. 그래도 conditional GAN의 시초격인 논문이기도 하고, PatchGAN의 아이디어도 흥미로우니 읽기에는 재밌는 논문이었습니다.
'GAN' 카테고리의 다른 글
| StarGAN(2018) (0) | 2022.05.17 |
|---|---|
| CycleGAN(2017) (0) | 2022.04.24 |
| LSGAN (2016) (0) | 2022.04.22 |
| Wasserstein GAN (2017), WGAN-GP (0) | 2022.04.21 |
| InfoGAN (2016) (0) | 2022.04.18 |



