
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Latent space
- GAN
- ICLR
- pix2pix
- DCGAN
- PatchDiscriminator
- PatchGAN
- clova
- StarGAN
- Markov Random field
- Mutual Information
- InfoGAN
- Computer Vision
- Gradien Vanishing
- Unsupervised learning
- PGGAN
- conditional GAN
- Ian GoodFellow
- Styletransfer
- Representation learning
- self-supervised learning
- Unsupervised Representation Learning
- LSGAN
- Image-to-image translation
- xai
- Generative model
- Today
- Total
AI with U-Seminar, Daneil Jeong
CycleGAN(2017) 본문
Image-to-image translation task는 입력 이미지와 출력 이미지간의 관계를 찾아내는 작업입니다. 기존의 연구는 주로 입력과 출력의 각각의 대응되는 쌍의 이미지(pair)를 사용하였는데, 사실 이러한 데이터셋을 구축하는 것은 쉬운 일이 아닙니다. 구축하는 데 비용이 많이 들기도 하고, 또 pair 자체가 많이 없거나 명확히 규정하기 힘든 경우도 있어 실제로 데이터셋 숫자 자체도 많지 않습니다.
GAN은 2014년에 처음 나온 이후로 다양한 분야에 활용되었습니다.
아래는 GAN 논문에 대한 리뷰입니다.
https://aijyh0725.tistory.com/12
Generative Adversarial Nets (2014)
GAN 논문 리뷰 첫번째입니다. 0. 배경 Generative Model은 초기 Boltzman machine으로 부터 시작하여 DBM(2009), VAE(2014)등이 등장하였습니다. Generative Model을 2개의 큰 특징으로 정의하면 아래와 같습니다...
aijyh0725.tistory.com
GAN을 이용하여 특정 입력 도메인 X에서 출력 도메인 Y으로 이미지를 생성할 수 있을 것입니다. 이를 GAN에서 쓰는 것처럼, Generator라고 명명하면 다음과 같이 식을 만들 수 있습니다.
G: X -> Y
Cycle GAN은 위와 같은 mapping에 더하여 새로운 mapping function을 하나 더 만듭니다. G에 inverse한 mapping인, 다시 말해 Y를 X domain으로 보내는 mapping F를 정의합니다.
F: Y -> X
만약 두 mapping function을 적절히 만들고 학습시켜 최적의 함수를 구할 수 있다면, 더이상 paired한 데이터셋은 필요하지 않을 것입니다. unpaired한 데이터에 대해서도 단순히 domain 간의 관계를 잘 학습할 수 있다면 image translation을 원활히 진행할 수 있을 것입니다.

무엇보다 cycle이라는 개념을 논문에서 강조하는 이유는 아래와 같은 식을 만족하기 위해서입니다.
F(G(x)) = x, G(F(y)) = y
즉, 단순히 domain을 연결시키는 mapping 함수 2개를 구하는 것에 그치지 않고, domain간의 데이터들이 실제로 짝을 지을 수 있도록 학습이 되는 것이 논문에서 설계한 objective의 목표입니다.
논문 링크는 아래와 같습니다.
https://arxiv.org/abs/1703.10593v7
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be a
arxiv.org
1. 논문 리뷰
화가들은 그림을 그릴 때 실제 풍경이나 사물을 이용합니다. 유명한 화가 모네가 있었다면, 어떠한 풍경을 보고 자신만의 '모네풍'으로 새로운 그림을 만들어내는 것이 가능할 것입니다. 이러한 사실을 인공지능 모델에도 적용할 수 있을까요? 즉 한 domain에서의 지식을(모네풍의 그림) 다른 domain에서의 지식(실제 풍경 이미지)으로 연결시켜 새로운 이미지를 만들어낼 수 있다면 굉장히 효과적인 image translation task가 될 것입니다.
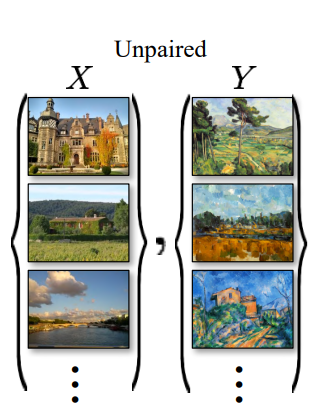
실제 세계는 위 그림과 같이 unpaired image들이 굉장히 많이 존재합니다. 인간은 이렇게 짝 지어있지 않는 데이터 도메인들 사이에서 지식과 정보를 연결시켜 특정 스타일의 이미지를 만들어내는 것이 가능합니다.
기계의 입장에서 생각해보면 어떨까요?
만약 특정 mapping function이 한 도메인에서의 특별한 특징(characteristic)을 찾애내고 이를 이용하여 다른 domain에서 활용할 수 있다면 굉장히 효과적일 것입니다. 이 때, 단순히 한 도메인에서 다른 도메인으로 넘어가는 방법(예를 들어 G:X-Y)만을 학습한다면 실제로 각각의 도메인의 이미지들이 짝을 지을 수 있는 의미가 있는 지 알기 어려울 것입니다. 심지어는 특정 이미지만을 만들어내거나(GAN에서 흔히 말하는 mode collapse) 혹은 잘못된 지식의 전달(bad optimization)을 통해 올바르지 않은 mapping function을 정의할 지도 모릅니다.
따라서, 양쪽 모두의 도메인에서의 지식을 서로 각각으로 전달할 수 있는 mapping을 배워야 합니다. 즉, cyclic한 방법으로 모델은 mapping 함수들을 학습해야 합니다. 이를 cycle consistent라 논문에서는 명명합니다.
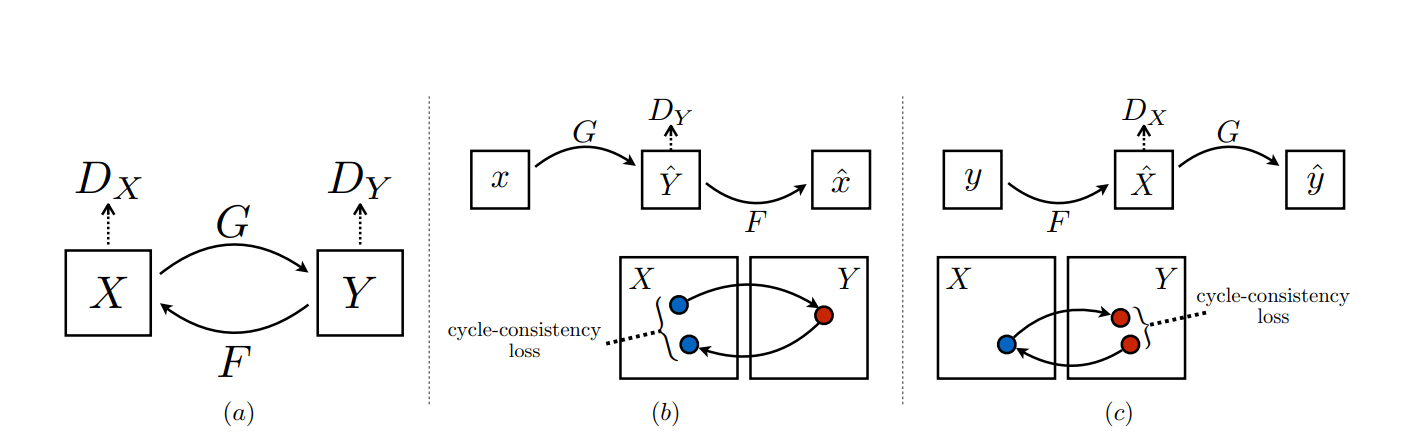
특정 도메인 X에서 Y로의 mapping 함수를 G라 했을 때, 이에 inverse mapping에 해당하는 F를 정의해줍니다. 2개의 mapping function은 도메인간의 지식을 전달하고 각 도메인간의 관계를 잘 정립하여 pair한 쌍의 데이터 분포를 갖는 데 도움을 줄 것입니다. 이에 더하여, 위 그림처럼 각각의 도메인에서 Discriminator를 사용합니다. 두 개의 Dicriminator를 갖는 시스템이 만들어졌습니다. 이 때 Discriminator는 PatchGAN 방식을 사용합니다 (patch size 70 x 70)
PatchGAN에 관련된 내용은 아래와 같습니다.
https://aijyh0725.tistory.com/17
Pix2Pix(PatchGAN, 2016)
Computer vision task 중에는 image를 또 다른 image로 바꾸는 task가 존재합니다. 위와 같이 어떠한 input 이미지를 이용하여 output 이미지를 만들어내는 것을 img-to-img translation, 혹은 style transfer 등..
aijyh0725.tistory.com
모델의 objective는 각각의 discriminator를 활용한 두 개의 adversarial loss와 cycle loss를 구성되게 됩니다.

이 때, Dx는 F(y)가 만들어내는 샘플과 X와의 관계를, Dy는 G(x)가 만들어내는 샘플과 Y와의 관계 사이에서 학습을 진행합니다. Cycle loss는 아래와 같이 mapping function을 두번 취한 형태와 각 domain을 비교하여 loss를 구합니다.
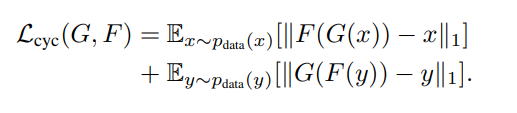
L1 loss와 adversarial loss 사이에 별 차이가 없어서 L1 loss를 단순히 사용하였다 하는데, 개인적으로 생각했을 때 이러한 방식때문에 blur 등 생성 이미지 퀄리티에 영향을 주었을 것 같습니다.
최종적으로 구하고자하는 최적의 G와 F는 아래와 같이 정의할 수 있습니다.
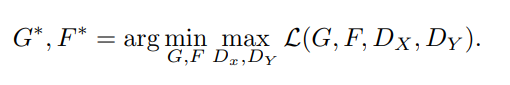
각각 G와 F, D를 학습함에 있어서는 LSGAN에서 제시한 least-square loss 방식을 사용하였습니다.
https://aijyh0725.tistory.com/16
LSGAN (2016)
GAN의 학습은 굉장히 불안정합니다. GAN의 학습 불안정 중, 특정 샘플에 대하여 gradient vanishing 문제가 발생하는 경우가 있습니다. Discriminator의 decision boundary (real과 fake를 구분하는)에서 멀리 떨..
aijyh0725.tistory.com
least-square 방식에 대하여 궁금하신 분들은 위 링크를 참조하시기 바랍니다.
model의 oscillation을 방지하기 위하여, D를 학습함에 있어서는 G가 만들어낸 50가지의 샘플들을 종합하여 사용하였다 합니다. (단순히 한 step의 Generated sample을 이용하는 것이 아니라)
2. 결과 및 한계점
결과 비교는 pix2pix 방식을 사용하여 진행했습니다.
그 중에서도 pix2pix 방식과 직접적으로 비교한 사진 몇장을 보면,


성능 자체는 확실히 pix2pix가 뛰어나지만, unpaired 데이터셋을 이용하여 pix2pix에 거의 근접한 결과물을 내었다 자부하고 있습니다. 실제 practical한 상황에서는 unpaired한 데이터셋을 사용하는 것이 굉장히 효과적일 수 있으니 어느 정도 contribution이 있다 생각할 수 있습니다.
Loss function의 각 부분에 대한 ablation study도 있습니다.

위 그림에서 볼 수 있는 것처럼, 모든 loss를 쓰지 않을 경우 굉장히 결과물이 안좋습니다. 그나마, GAN+foward 정도는 좋은 결과물을 만들고 있으나, mode collapse의 문제로 다양한 이미지를 생성하지 못한다고 합니다. 이러한 ablation study를 통해 자신들이 정의한 loss function이 효과적임을 주장하고 있습니다.

특히, CycleGAN은 color나 texture 변화에 있어서 한계점을 많이 보였는 데, 특정 도메인 혹은 task에 대하여 identity loss(G(y) - y )를 사용하면 어느 정도 완화가 가능하다고 합니다. 그러나, 위처럼 일반화하기 어려운 방법론은 굉장히 한계를 지닌다고 논문에서도 말하고 있습니다.
또 다른 한계점과 관련된 결과를 보겠습니다.

고양이를 강아지로 바꾸는 것처럼, domain에 geometric한 변화를 가져오는 것은 어렵다 합니다. 즉 domain간의 연관성도 모델의 성능에 굉장히 큰 영향을 끼치는 요소 중 하나입니다.
가장 오른쪽에 horse->zebra의 예시를 통해, domain 사이의 불균형한 데이터 분포(사람 이미지가 zebra에는 없음)도 영향을 미칠 수 있다 합니다. 한 쪽 domain의 bias를 다른 domain에서 얻을 수 없기 때문에, 어떠한 부분을 변경해야 하는 지 알기 어렵게 됩니다.
이렇듯, cycleGAN은 unpaired한 데이터셋에 대하여 굉장히 선구적인 방법론을 제시하고 있습니다만, 많은 한계점에 직면하였습니다. 추후 논문들은 이러한 한계점을 어떻게 해결할 지 궁금합니다.
'GAN' 카테고리의 다른 글
| StarGAN(2018) (0) | 2022.05.17 |
|---|---|
| Pix2Pix(PatchGAN, 2016) (0) | 2022.04.23 |
| LSGAN (2016) (0) | 2022.04.22 |
| Wasserstein GAN (2017), WGAN-GP (0) | 2022.04.21 |
| InfoGAN (2016) (0) | 2022.04.18 |



